* 김성훈 교수님의 유튜브강의를 공부 목적으로 정리하여 작성하였습니다.

실제 주어진 y값과 H(x)인 예측값을 얼마나 잘 예측했느냐의 cost 함수를 구할 것이다.
학습을 한다는 이야기는 W, b를 조정해서 가장 작은 cost값을 찾아나간다는 말이다.
# TensonFlow Mechanics

step-1) 그래프를 build 한다.
step-2) sess를 통해 실행을 한다.
step-3) 변수들을 반복적으로 조정하여 가장 작은 cost를 찾는다.

step-1)
X, Y에 대한 데이터가 주어졌다고 가정하고, 이제 W과 b를 정의해야 되는데
Variable이라는 노드로 정의할 수 있다. 여기서 Variable 개념은 프로그래밍에서의 변수의 의미와는 조금 다르다.
Tensorflow가 사용하는 Variable이다. Tensorflow를 실행시키면 Tensorflow가 자체적으로 변경시키는 값이다.
다르게는 Trainable이라고 생각하면 쉽다. 학습하는 과정에서 자기가 값을 변경시킨다고 보면 된다.
* tf.reduce_mean( ): 평균 내주는 tf 메소드

Cost를 Minimize하는 방법 중 하나인 GradientDescent를 사용한다.
.minimize() 메소드는 무엇을 최소화할 것인지 나타내며, 여기서는 cost를 최소화할 것이다.
그러면 우리가 위에서 정한 W와 b값을 스스로 조정하여 최소화 값을 찾아낸다.
여기까지 그래프가 그려졌다.
step-2)

우리가 정한 W, b 초기값을 사용하려면 tf.global_variables_initializer()를 먼저 실행시켜줘야 한다.
위에서 minimize(cost)하는 작업을 train이라는 이름에 담아놓았다. train이라는 아이를 실행시켜야 optimizer.minimize(cost)하게 된다.
총 2001번 수행할 for문을 작성하고, train을 실행시킨다. 그리고 각 스텝을 다 출력하기는 힘드니까, 20번에 1번씩 출력하게끔 조건문을 작성하였다. 그래서 해당 스텝마다 cost, W, b값을 확인해보자.
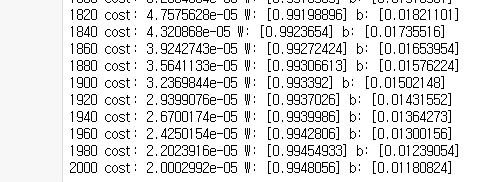
-> 실행 결과, (x*1 + 0 = y)처럼 우리가 원했던 결과가 나온다.
# placeholder 개념
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b
print(sess.run(adder_node, feed_dict={a: 3, b: 4.5}))
print(sess.run(adder_node, feed_dict={a: [1, 3], b: [2, 4]}))7.5
[3. 7.]
Placeholders는 우리가 직접 값을 주지 않고, 필요 할 때 값을 던져주는 것이다.
즉, 선언과 동시에 초기화 하는 것이 아니라 일단 선언 후 그 다음 값을 전달한다.
여기서 값을 전달한다고 되어 있는데 이는 다른 텐서(Tensor)를 placeholder에 맵핑시키는 것이라고 보면 된다.
값을 할당하기 위해서는 feed dictionary라는 것을 활용하게 되는데, 세션을 생성할 때 feed_dict의 키워드 형태로 텐서를 맵핑 할 수 있다.
- placeholder(dtype, shape=None, name=None)의 전달 파라미터는 다음과 같다.
* dtype : 데이터 타입을 의미하며 반드시 적어주어야 한다.
* shape : 입력 데이터의 형태를 의미한다. 상수 값이 될 수도 있고 다차원 배열의 정보가 들어올 수도 있다.
* name : 해당 placeholder의 이름을 부여하는 것으로 적지 않아도 된다.
W = tf.Variable(tf.random_normal([1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# our hypothesis
hypothesis = X*W + b
# Now we can use X and Y in place of x_data and y_data
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# cost function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# minimize
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 0.01)
train = optimizer.minimize(cost)
# launch the graph
sess = tf.Session()
# initializes global variables
sess.run(tf.global_variables_initializer())
# fit the line
# train으로 나오는 values는 중요하지 않으니까, _로 처리하였음
for step in range(2001):
cost_val, W_val, b_val, _ = sess.run([cost, W, b, train], feed_dict={X: [1,2,3], Y:[2.1,3.1,4.1]})
if step % 20 == 0:
print(step, cost_val, W_val, b_val)이제 train을 실행시킬 때, X와 Y의 값을 feed_dict로 넘겨줄 수 있게 된다.
또한 sess.run(cost), sess.run(W), sess.run(b), sess.run(train) 각각 실행시킬 수도 있지만, 리스트를 사용하여
sess.run([cost, W, b, train])으로 한번에 실행이 가능하다.
# 그럼 알고리즘이 X값에 따라 hypothesis를 잘 수행했는지 Testing 해보자!
print(sess.run(hypothesis, feed_dict={X: [1.5, 3.5]}))>>> [2.5981503 4.6007195]
X값에 따라 training시켰던 Y값 value와 거의 비슷한 추세로 결과가 나온다.
'머신러닝과 딥러닝 > 실습' 카테고리의 다른 글
| TensorFlow로 Logistic Classification의 구현 및 당뇨병 예측 실습 (0) | 2020.02.13 |
|---|---|
| TensorFlow로 파일에서 데이터 읽어오기 (0) | 2020.02.11 |
| TensorFlow로 Multi-variable Linear Regression 실습 (0) | 2020.02.11 |
| 장르 유사도 기반 영화 추천 시스템 / Scikit-Learn의 문제점 (0) | 2020.01.28 |



댓글