동시성(Concurency)으로 프로그램 속도 개선
What Is Concurrency?
파이썬은 동기 방식으로 동작하도록 설계된 언어다. 그래서 파이썬에서는 thread, task, multiprocess 모듈를 사용해서 동시적으로 작업들을 처리할 수 있다. 고수준에서보면 세 가지 방법 모두 어떤 작업들을 동시에 처리한다는 점이서 비슷해보이지만, 내부를 파보면 서로 조금씩 다른 점이 있다.
쓰레드를 사용하는 threading 모듈, task를 사용하는 asyncio 모듈, 프로세스를 사용하는 multiprocessing 모듈이 있는데 이 중 정말로 동시에 병렬적으로 작업을 처리하는 것은 multiprocessing 뿐이다. threading과 asyncio 모듈은 모두 하나의 프로세서를 사용하기 때문에 한 번에 하나씩 작업을 실행할 수 밖에 없다. 다만, 서로 돌아(루프)가면서 교묘하게 진행 순서를 겹쳐서 전체 작업 시간을 줄이는 것이다. 이런 방법은 엄밀하게는 여러 작업들을 한꺼번에 같은 시간에 처리하는 것은 아니지만, 동시적인 작업 처리라고 부른다.
threading과 asyncio는 동시적인 작업을 할 때 멀티 쓰레드 또는 작업들 간에 서로 돌아가면서 처리하는 방법에서 큰 차이가 있다. threading 모듈에서는 실행되고 있는 각 쓰레드를 운영체제가 언제든지 멈추고 다른 쓰레드를 진행시킬 수 있다. 운영체제가 쓰레드를 선점할 수 있기 때문에, 이걸 선점형 멀티태스킹(pre-emptive multitasking)이라고 한다.
선점형 멀티태스킹은 쓰레드 안의 코드가 아무것도 안해도 알아서 스위칭이 일어나기 때문에 편한 점도 있지만, 언제든지 스위칭이 일어날 수 있다는 점에서는 다루기 어려워질 수 있다. x = x + 1 같은 코드를 돌리다가도 스위칭이 일어날 수 있기 때문이다. 반면에, asyncio 모듈은 비 선점형, 협력식 멀티태스킹(cooperative)방식을 사용한다. 이 방식은 각 작업이 언제 스위칭될 준비가 되었는지 직접 명시해주어야 한다. 이 말은 결국 asyncio를 사용하려면 코드를 약간 수정해줘야한다는 뜻이기도 하다. 이 방식의 장점은 언제 다른 테스크로 넘어갈 지를 항상 알 수 있다는 점이다. 다른 테스크로 넘어갈 수 있는 지점에 이르기 전까지는 절대로 넘어갈 일이 없다.
하나의 프로세스 안에서 여러 스레드가 실행되면 이 스레드들은 CPU와 메모리라는 한정적인 자원을 서로 사용하려고 경쟁하게 된다. 운영체제는 하나의 스레드가 자원을 무한정 점유하는 문제를 막기 위해 스케줄링을 하는데, 이 스케줄링 방식에 선점형(Preemptive)과 비선점형(Non-preemptive) 방식 2가지가 존재한다. 선점형은 강제로 실행권을 빼앗기는 것이고, 비선점형은 실행 주체가 자신의 실행권을 자발적으로 내려 놓는 것을 의미한다.
What Is Parallelim?
| 동시성 유형 | 스위칭 결정 방법 | 프로세서 수 |
| 선점형 멀티태스킹 (threading) 단일 프로세스, 다중 스레드 |
운영체제가 언제 스위칭 할지를 결정 | 1 |
| 협력식 멀티태스킹 (asyncio) 단일 프로세스, 단일 스레드 |
Task가 언제 스위칭 할지를 결정 | 1 |
| 멀티프로세싱 (multiprocessing) 다중 프로세스 |
프로세스들이 서로 다른 CPU에서 동일한 시간에 병렬적으로 실행 | 여러 개 |
threading과 asyncio 모듈이 하나의 프로세서에서 동시성을 구현했다면 multiprocessing 모듈은 파이썬에서 완전히 새로운 프로세스를 생성한다. 새로운 프로세스를 생성한다는 것은 별개의 자원들을 할당받은 새로운 파이썬 인터프리터를 실행하는 것으로 볼 수 있다.
완전히 다른 프로세스이기 때문에 다른 CPU 코어를 사용해서 실행할 수 있고, 완전히 같은 시간에 병렬적으로 실행할 수 있다는 뜻이다. 이런 식으로 실행 하는데에는 몇 가지 복잡한 문제들이 따르긴 하는데, 파이썬은 이 문제들을 대체로 잘 처리하는 편이다. 이제 동시성과 병렬성에 대해 알았으니 그 차이를 정리해본다.
When Is Concurrency(동시성) Useful?
동시성은 CPU bound와 I/O bound로 알려진 두 가지 문제에 대해 큰 차이를 만들 수 있다.
- CPU Bound: CPU에서 처리해야 하는 시간이 많은 작업(대부분 연산 작업)
- I/O Bound: I/O 처리에 필요한 시간이 많은 작업
I/O Bound 작업은 프로그램 외부에서 입/출력 작업이 처리될 때까지 프로그램 내부에서는 기다리고 있어야 하기 때문에 프로그램이 느려지게 만들 수 있다. 프로그램을 느려지게 만드는 주요 원인은 외부 자원(파일시스템, 네트워크 커넥션)으로부터 Input/Output(I/O)를 자주 기다려야 하는 데에 있다. 이런 I/O 작업으로 CPU는 계속 놀고 있어야 한다. 이럴 때는 I/O를 위한 더 빠른 메모리, 하드디스크, 네트워크 성능이 좋아져야 프로그램의 성능이 향상된다.

위 그림에서 파란색 박스는 프로그램이 진행 중인 시간을 나타내고, 빨간색 박스는 I/O 바운드 작업이 끝날 때까지 대기하는 시간을 나타낸다. 실제로 빨간색 박스는 파란색 박스보다 훨씬 크며 프로그램은 대부분의 시간을 I/O 바운드 작업을 대기하는데 보내게 된다.
반면, 네트워크나 파일에 엑세스하는 작업 없이 연산 작업만 하는 프로그램들도 있는데 이런 작업들을 CPU 바운드 작업이라고 하고 이 프로그램의 속도를 제한하는 것은 CPU다. 이런 작업들은 CPU의 쿨럭 속도가 빨라져야 전체 프로그램의 성능이 향상될 수 있다.

나중에 살펴볼 예제를 통해 알게 되겠지만 여러가지 동시적 처리 방법들은 CPU 바운드이냐, I/O 바운드냐에 따라 프로그램에 도움이 될 수도 있고, 오히려 악화시킬 수도 있다. 동시성을 프로그램에 도입하는 것은 코드가 더 늘어나고 복잡성 또한 높아지는 작업이기 때문에 동시성이 실제로 프로그램의 성능을 개선하는데 도움이 되는지 잘 결정해야 한다.
| I/O 바운드 프로세스 | CPU 바운드 프로세스 |
| 프로그램은 대부분의 시간을 네트워크 연결, 하드 드라이브, 프린터와 같은 느린 외부 장치와 통신하는데 보낸다. | 프로그램은 대부분의 시간을 CPU 작업을 하는데 보낸다. |
| 외부 장치의 응답을 기다리는 대기 시간들을 잘 겹쳐야(Overlapping) 전체적인 속도를 개선할 수 있다. | 속도를 높이려면 같은 시간에 더 많은 계산을 할 수 있는 방법을 찾아야 한다. |
How to Speed Up an I/O-Bound Program
I/O 바운드 프로그램의 속도를 개선하는 방법을 알아보기 위해서 웹사이트 몇 개로부터 페이지를 다운로드하는 프로그램을 만들어보자.
1. Synchronous Version(동기 버전)
먼저 해당 작업을 동시성(concurrency)이 없는 동기 작업으로 시작해보자. 파이썬은 기본적으로 테스트할 프로그램은 requests 모듈이 필요하다. 때문에 프로그램을 실행하기 전에 pip install requests를 실행해야 한다.
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 20
start_time = time.time() # 함수가 시작되었을 때의 시간
download_all_sites(sites)
end_time = time.time() # 함수가 종료되었을 때의 시간
duration = end_time - start_time # 함수를 실행하는 데 걸린 총 시간
print(f"Downloaded {len(sites)} in {duration} seconds")굉장히 간단한 프로그램이다. download_site 함수가 그냥 주어진 URL로부터 내용을 다운받아와서 그 크기를 출력한다. 네트워크 통신을 위해서 requests 모듈의 Session 객체를 사용하였다. 그냥 바로 get() 메서드를 사용할 수도 있지만, Session 객체를 만들어서 사용하면 몇 가지 네트워킹 트릭들을 내부적으로 수행해주기도 하고, 속도를 높이는데도 유용하다. download_all_sites 함수는 사이트 URL 목록을 받고, Session 객체를 생성하여 download_site 함수에 넘겨주어 목록을 하나씩 돌면서 순차적으로 데이터를 다운받게 한다. 비교를 위해 작업이 모두 끝나면 시간이 얼마나 걸렸는지 출력하도록 하였다.
이 프로그램은 위에서 보았던 I/O 바운드 작업을 시각화한 그림과 거의 흡사한 과정으로 실행된다.
동기 버전의 장점
작성하기도 쉽고 이해하기도 쉬워서 디버깅하기도 쉽다. 순차적인 과정으로 하나의 작업이 완료된 것을 확인한 뒤, 다음 작업을 진행하기 때문에 프로그램이 어떻게 작동하는지 쉽게 예측할 수 있다.
동기 버전의 문제
가장 큰 문제는 느리다는 점이다. 아래는 위 프로그램을 실행한 결과의 예이다.

그렇지만 느리다는 것은 항상 큰 문제는 아니다. 만약 프로그램이 동기 버전으로 한 번 실행하는데 2초 정도 걸리고 자주 실행하는 것도 아니라면, 동시성을 추가할 필요는 없을 것이다.
그런데 만약 자주 실행되어야 하는 프로그램이라면? 또는 한 번 실행하는데 몇 시간이 걸리는 프로그램이라면?
이런 경우 Threading을 사용하여 프로그램을 재작성하면서 동시성으로 넘어가 보자.
2. threading Version
threading 모듈을 사용해서 위의 프로그램을 개선시켜보자. threading 버전으로 프로그램을 만드는 데는 순차적인 프로그램을 만드는 것 보다 좀 더 많은 노력이 들어간다.
다음은 위의 프로그램을 threading 모듈을 사용해서 개선한 버전이다.
from concurrent.futures import ThreadPoolExecutor
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 20
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")threading 모듈을 추가하려면, 전체 구조는 같지만 약간의 변경이 필요하다. download_all_sites() 함수가 사이트 목록에 있는 사이트 하나마다 download_site 함수를 실행하는 대신, 더 복잡한 구조로 바뀌었다.
이 버전에서는 ThreadPoolExecutor를 사용하였는데, Thread + Pool + Executor로 분리해서 볼 수 있다. Thread는 작업 하나의 실행 단위다. Pool이 흥미로운 부분인데, ThreadPoolExecutor 객체는 각각 동시에 실행될 수 있는 쓰레드의 묶음인 Pool을 만들고 각각의 Thread를 동시에 실행한다. 마지막으로 Executor는 Pool에 있는 각각의 Thread를 언제, 어떻게 실행될 지를 제어하는 부분이다. ThreadPoolExecutor도 Context Manager이기 때문에 with 문법을 사용하여 간편하게 Threads Pool을 만들 수도 해제할 수도 있다.
ThreadPoolExecutor를 만들면 map(function, iterable) 메서드를 사용할 수 있다. 이 메서드는 iterable 객체와 객체 안의 각 요소에 적용시킬 함수 하나를 받는다. ex. list(map(요소마다 +1을 더해주는 함수, [1,2,3,4,5])) => [2,3,4,5,6]
여기서 놀라운 점은 각 항목에 함수를 실행시키는 작업이 쓰레드의 Pool을 이용하여 동시적으로 실행된다는 점이다.
다른 언어나 Python2 버전을 사용하던 사람들은 Threading을 다룰 때 Thread.start(), Thread.join() 그리고 Queue과 같은 익숙했던 부분을 다루는 객체와 함수가 어디에 있는지 궁금할 것이다. 그 객체와 함수들은 그대로 존재하며, 쓰래드에 대한 정밀한 제어가 필요하다면 그것들을 직접 사용해서 구현할 수도 있다. 하지만 파이썬 3.2 버전부터 표준 라이브러리에서 Excecutor라고 불리는 고수준의 추상화된 객체를 추가했다. 정밀한 제어가 필요한 경우가 아니라면 이 객체를 사용하면 된다.
이 예제에서 흥미로운 부분은 각각의 쓰레드가 각자의 request.Session() 객체를 생성해서 사용한다는 점이다. 확실하지는 않지만, requests 문서를 살펴볼 때 https://github.com/not-kennethreitz/requests/issues/2766 이 이슈를 확인하면 각 Thread마다 별도의 Session 객체를 생성해주어야 하는 것으로 보인다.
threading을 사용하면서 흥미로우면서도 어려운 부분이 이런 부분인데, 선점형 멀티태스킹에서는 운영체제가 한 작업을 멈추고 다른 작업을 실행할 때 쓰레드끼리 공유하는 데이터들을 보호(thread-safe)할 수 있게 관리한다. 그러나 requests의 Session 객체는 thread-safe하지 않다. 물론 데이터가 무엇이고 어떻게 사용되는지에 따라 데이터를 thread-safe하게 만들 수 있는 몇 방법이 있다.
그 중 하나는 파이썬의 queue 모듈에 있는 Queue 객체 같은 쓰레드 안전한 자료 구조를 사용하는 것이다. 이런 객체들은 threading.Lock 같은 저수준 요소들을 사용해서 동일 시간에 오직 하나의 쓰레드만 코드 조각 또는 메모리에 접근하는 것을 보장해준다. 그리고 ThreadPoolExecutor를 사용하면 이 방법을 간접적으로 사용하게 된다.
예제에서 사용한 또다른 방법은 thread local storage라는 것을 사용하는 방법이다. Threading.Local()은 전역 변수 같은 객체를 생성하지만 실질적으로는 각 Thread마다 고유하다. 예제에서는 threadLocal 변수와 get_session() 함수를 사용해서 이 부분을 구현하였다.
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
------------------------------------------------------------------
# 파이썬 빌트인 함수
>>> hasattr(object, name)
object에 name 속성(attribute) 존재를 확인한다.
만약 인자로 넘겨준 object에 name 속성이 존재하면 True, 아니면 False를 반환
class obj:
data = 1
def b(self):
pass
hasattr(obj, 'b')
>> True
x = obj()
hasattr(x,'data')
>> TrueThreadLocal 객체는 threading 모듈에 포함되어 있으며, 이러한 용도로 사용되기 위해 만들어졌다. 좀 이상하게 보이겠지만, 전역적으로 하나만 만들어 놓으면 내부적으로 각각의 쓰레드마다 서로 다른 데이터에 접근하도록 처리해준다.
get_session()이 호출되었을 때, Session은 현재 동작하는 Thread에 고유하다. 그래서 각 Thread는 get_session()을 첫 번째 호출할 때 단일 Session을 만든다. 그리고나서 Thread 작업 내내 만들어진 Session을 사용한다.
마지막으로 Thread의 갯수에 대해 주목해보자. 예제에서는 5개의 Thread를 사용한다. 이 숫자를 조정하면서 전체적인 성능이 어떻게 변하는지 실험해보면 좋다. 다운로드할 사이트 하나마다 하나의 쓰레드를 생성하는 게 제일 빠를 것으로 생각할 수도 있는데, 적어도 내 컴퓨터에서는 아니었다. Thread 5~10개의 사이에서 가장 높은 성능 향상을 가져왔다. 10개보다 더 많이 생성하면, 쓰래드를 만들고 삭제하는 추가 오버헤드 때문에 실행 속도가 상쇄된다.
따라서 적절한 Thread의 개수는 task 단위의 상수가 아니라, 몇 번의 실험을 통해서 정해야 한다.
threading 버전의 장점
빠르다. 동기 버전이 대략 7초 정도 걸렸지만, 스레드 버전은 2초로 훨씬 빠르다.
다음은 threading 버전의 실행 시간을 나타낸 다이어그램이다.
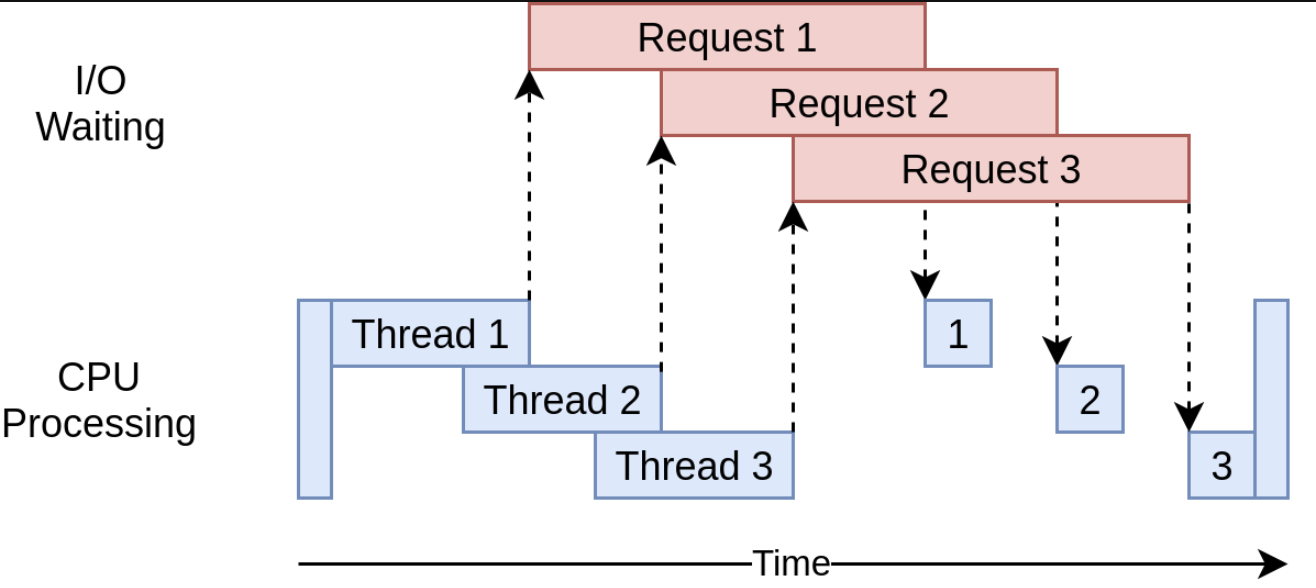
여러 개의 웹사이트에 요청을 보내기 위해 여러 개의 쓰레드를 사용해서, 각 쓰래드가 I/O 작업을 대기하는 시간을 겹치게 만들었다. 결국 전체적인 속도 향상으로 이어졌다.
threading 버전의 문제점
예제에서 봤듯이 추가 코드가 필요하고, 스레드 간에 어떤 데이터를 공유해야 할 지 잘 생각해야 한다. 특히 Thread 간에 상호 작용은 알아내기 쉽지 않다. 이런 상호 작용은 무작위로, 간헐적으로 일어나는 버그의 원인이 되는 경쟁 상태(Race Condition)를 발생시킬 수 있다. 이런 버그는 굉장히 디버깅하기 어렵다.
3. asyncio Version
Asyncio 예제 코드로 들어가기전에 잠깐 Asyncio 작업에 대해 알아보려고 한다.
1) Asyncio 기초
Asyncio의 전반적인 컨셉은 이벤트 루프(event loop)라고 하는 하나의 파이썬 객체가 각 Task를 언제 어떻게 실행시킬 지를 관리하는 것이다. 이벤트 루프는 각 Task가 어떤 상태에 있는지 알고 있다. 실제로는 Task들이 여러가지 상태에 있을 수 있지만, 여기서는 단순화해서 두 가지 상태만 있다고 가정해보자.
하나는 준비 상태로 이 상태에 있는 Task는 해야할 작업이 있으며, 그 작업을 실행할 준비가 되어 있다는 것이다. 또 하나는 대기 상태인데 이 상태에 있는 Task는 네트워크 통신 같은 외부 작업이 끝나기를 대기하는 상태이다. 단순화 한 이벤트 루프는 2가지 상태 중에서 하나를 선택하고 실행한다. 준비 상태에 있는 Task를 하나 꺼내서 실행시키는데, 이 테스크는 직접 이벤트 루프에게 다시 제어권을 반환할 때까지 완전한 제어권을 가지게 된다.
실행 중이던 테스크가 이벤트 루프에 제어권을 넘기면, 이벤트 루프는 그 테스크를 준비 또는 대기 목록에 다시 추가하고, 대기 목록의 테스크들을 확인하여 I/O 작업이 끝나서 준비 상태인 태스크가 있는지 확인한다. 준비 목록에 있는 태스크들은 아직 실행된 적이 없으므로 그대로 준비 상태이다.
모든 태스크가 상태 별로 정렬되었으면, 이벤트 루프가 실행시킬 다음 테스크를 선택한다. 새로 선택한 테스크에 대해서 앞의 과정들을 반복하게 된다. 이벤트 루프는 가장 오랫동안 대기 상태였던 태스크를 선택해 실행시킨다. 이벤트 루프가 끝날 때까지 이 과정이 계속 반복된다.
Asyncio의 중요한 점은 Task가 직접 의도적으로 제어권을 반환하지 않는 이상 절대로 스위칭이 일어나지 않는다. 이러한 이유는 Task는 절대로 실행 중간에 중단되지 않기 때문이다. 그러므로 Asyncio가 threading 모듈보다 자원을 더 쉽게 공유할 수 있게 된다. 코드를 thread-safe 하게 짤 필요가 없어지기 때문이다.
고수준 관점에서 바라본 asyncio 모듈에 대해 알아보았는데, 더 깊은 내용은 아래 페이지를 참고. https://realpython.com/python-concurrency/#what-is-parallelism
async와 await
이제 파이썬에 추가된 두 가지 키워드 async와 await에 대해 알아본다.
await 키워드는 위에서 알아본 내용들 중에 Task가 이벤트 루프에게 다시 제어권을 반환하는 일을 가능케하는 일종의 magic 키워드다. 코드에서 어떤 함수 호출을 await 한다면, 그 함수 실행이 어느 정도 시간이 걸리니까 Task가 제어권을 넘겨줘야 한다는 신호이다. async 키워드는 지금 정의하려는 이 함수가 내부에서 await 키워드를 사용한다는 의미로 간단히 생각할 수 있다. 비동기 generators처럼 그렇지 않은 경우도 있지만, 대부분의 경우에는 맞기 때문에 처음 이해하는데 도움 될 것이다.
한 가지 예외는 async with 문인데, await 해야할 객체로부터 컨텍스트 매니저를 생성하는 기능을 한다. 의미는 조금 다를 수 있지만 주요 아이디어는 똑같다. 이 컨텍스트 매니저를 통해 실행하는 도중에 멈추고 다른 Task로 넘어갈 수 있음을 의미한다.
당연하게도 이벤트 루프와 태스크들 간의 상호 작용을 관리하는 것은 복잡한 일이다. 일단은 await를 내부에서 사용하는 함수는 꼭 async def로 정의되어야 한다는 사실만 알고 시작하면 된다. 그렇지 않으면 syntax error가 발생할 것이다.
Back to Code
asyncio의 기본 원리에 대해 알았으니, 앞의 예제를 asyncio 버전으로 이해해보자. Note that this version adds aiohttp. You should run pip install aiohttp before running it.
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 20
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")이 버전은 앞의 두 버전보다 좀 더 복잡하다. 비슷한 구조를 가지고는 있지만, ThreadPoolExecutor를 쓰는 것보다는 더 많은 작업이 들어갔다. 위에서부터 살펴보자.
- download_site()
download_site 함수는 threading 버전과 거의 동일하지만, 함수 정의 부분에 async 키워드를 사용한 점과 내부에서 session.get() 을 호출할 때 async with 문을 사용했다는 점이 다르다. 왜 thread local storage 대신 Session 객체가 async with 문에 사용될 수 있는 것인지는 좀 있다 살펴볼 것이다.
- download_all_sites()
download_all_sites 함수는 threading 버전과 비교해서 가장 크게 바뀐 부분이다. 모든 Task에게 session 객체를 공유시킬 수 있도록 컨텍스트 매니저를 사용하여 session을 생성하였다. Task들이 같은 session 객체를 공유할 수 있는 이유는 모든 Task들이 같은 쓰레드에서 동작 때문이다. session이 나쁜 상태에 있는 동안 한 Task가 다른 Task를 방해할 수 없다.
컨택스트 매니저 내부에서는 Task들을 시작시키는 일에도 관여하는 asyncio.ensure_future()를 사용하여 테스크의 목록을 만든다. 모든 Task가 생성되고 나면, asyncio.gather()를 사용하여 모든 태스크가 끝날 때까지 Session context를 유지하게 한다.
threading 버전에서도 이와 비슷한 과정을 거치지만, threading버전은 세부 사항을 ThreadPoolExecutor 내부에서 알아서 처리하는 반면 asyncio는 AsyncioPoolExecutor class 같은 건 없다.
작지만 큰 차이점이 하나 더 있는데, threading 모듈에서는 쓰래드 풀에 들어갈 쓰레드 최적의 개수에 대해 명확하지 않았다. threading 모듈에 비해 asyncio 모듈이 가지는 가장 큰 강점은 각 Task는 쓰레드를 만드는 것보다 훨씬 더 적은 자원과 시간을 소모한다는 것이다. 그렇기 때문에 쓰레드를 사용할 때보다 더 많은 태스크를 만들어 동시에 실행하는 것이 가능하다. 이 예제에서는 한 사이트마다 각각 별도의 태스크를 만들어 주는데 잘 작동한다.
- __main__
마지막으로 asyncio의 본질은 이벤트 루프를 시작시키고 이벤트 루프에게 Task를 실행하라고 명령해주는 것이다. 맨 아래에 있는 __main__ 부분에서 get_event_loop()를 사용하여 이벤트 루프를 가져오고, run_until_complete()를 사용하여 태스크들을 실행시킨다.
파이썬 3.7부터는 get_event_loop()와 run_until_complete()를 사용하는 대신에 asyncio.run() 하나를 사용하면 된다.
주피터 노트북에서 실행 오류
Jupyter asyncio RuntimeError: This event loop is already running주피터 노트북은 자체적으로 이벤트 루프를 사용하고 있어서 생기는 오류다. 아래의 코드를 추가하여 실행
!pip install nest_asyncio
import nest_asyncio
nest_asyncio.apply()
asyncio 버전의 장점
테스트 해본 결과 지금까지 중에 가장 빠른 버전이다.

실행 시간 다이어그램을 보면 threading 모듈과 비슷한 것을 볼 수 있다.
Asyncio버전은 단지 I/O 요청들이 모두 하나의 쓰레드에 의해 이루어진다는 점만 다르다.
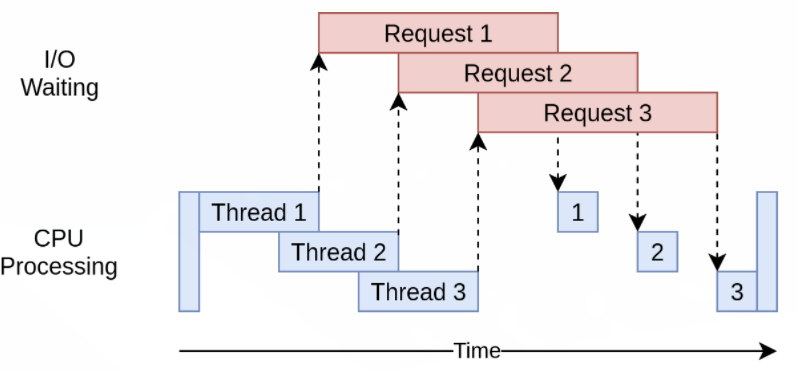
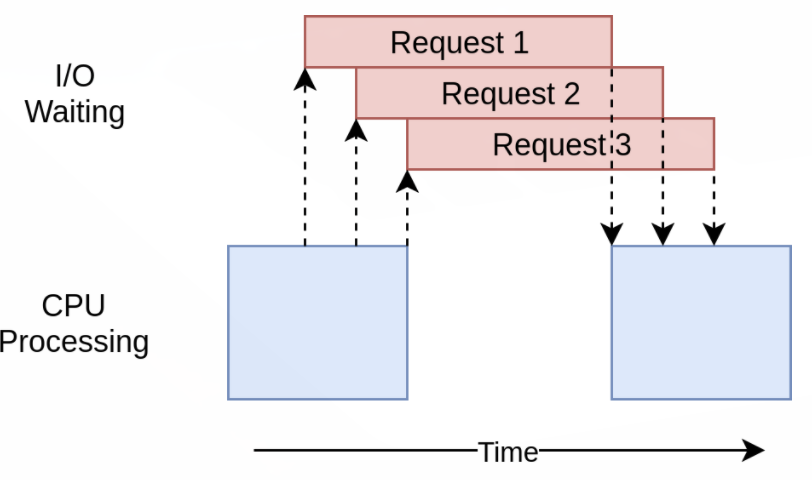
작동은 비슷하지만 ThreadPoolExecutor같은 고수준 객체가 없는 점은 threading 모듈에 비해서 코드 복잡도를 높게 만든다. 이 시점이 바로 더 나은 성능을 위해 추가 작업이 필요한 시점이다.
또한 async 와 await 문을 적절한 곳에 넣어주는 것도 필요하기 때문에 더 복잡해진다는 의견도 있다. 그러나 Task가 언제 교체될 지를 생각하면서 코드를 짜야하기 때문에 더 빠르고 더 좋은 디자인을 만드는데 도움이 된다.
스케일링 문제도 크게 개선되는데, 위의 threading 버전에서 각 사이트마다 하나 씩 쓰래드를 할당하는 것은 적당한 수의 쓰래드를 할당하는 것보다 훨씬 느렸다. asyncio 버전에서는 수백개의 태스크를 만들어도 전혀 느려지지 않는다.
asyncio 버전의 문제점
asyncio 버전도 역시 몇 가지 문제점이 있다. 일단 asyncio를 최대한 활용하려면 동시성을 지원하는 라이브러리들이 필요하다는 점이다. 만약 사이트를 다운로드하는데 requests 라이브러리를 사용했다면 많이 느릴 것이다. requests 라이브러리은 이벤트 루프에 block 되었다고 알릴 수 있게 설계되지 않았기 때문이다. 이 문제점은 점점 더 많은 라이브러리들이 asyncio와 호환되도록 작성되고 있기 때문에 시간이 지날수록 해결되고 있다.
또 다른 문제는 어느 한 Task가 협력하지 않으면 협력적 멀티태스킹의 이점이 모두 사라진다는 점이다. 실수로 한 Task가 프로세서를 오랫동안 사용하고 있으면, 다른 Task들은 절대로 진행되지 못하고 묶여있게 된다. Event loop는 만일 Task가 제어권을 반환하지 않을 때 Task를 중단시킬 수 있는 방법이 없다.
이를 염두해두고, 근본적으로 다른 접근인 Multiprocessing에 대해 알아보자.
4. Multiprocessing Version
앞 버전들과 달리, multiprocessing 버전은 컴퓨터가 가진 여러 개의 CPU 코어들을 모두 사용할 수 있는 장점이 있다.
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 20
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Asyncio 예제보다 코드가 짧고 Threading 버전와 매우 비슷하다. 그럼 Multiprocessing이 무엇을 하는지 코드를 살펴보도록 하자.
multiprocessing 간단히 살펴보기
지금까지 살펴본 동시성 프로그래밍 예제들은 단일 CPU 코어 만을 사용하는 예제들이었다. 그 이유는 현재 CPython의 디자인과 Global Interpreter Lock(GIL) 이라는 것 때문이다. 이 글에서는 GIL에 대해 다루지 않을 것이다. 지금은 동기 버전, threading 버전, asyncio 버전 모두 하나의 CPU를 사용한다는 것을 아는걸로 충분하다.
multiprocessing은 GIL을 우회해서 코드를 여러 개의 CPU 상에서 사용할 수 있도록 만들어졌다. 새로운 파이썬 인터프리터를 각각의 CPU에서 실행할 수 있도록 만들어주는 것이다. 새로운 인터프리터를 만드는 것은 쓰레드를 생성하는 것 보다는 훨씬 무겁고 어려움도 많지만, 올바르게 사용된다면 프로그램의 성능을 크게 개선할 수 있다.
multiprocessing 코드
multiprocessing 버전 코드는 synchronous 버전에 비해서 약간의 차이가 있다. download_all_sites 함수에서 download_site 함수를 반복적으로 호출하는 대신 multiprocessing.Pool 객체를 생성해서 threading 버전과 비슷하게 download_site 함수를 sites 리스트에 맵핑한다.
여기서, Pool 객체가 여러 개의 Python interpreter 프로세스를 생성하고 각각이 download_site 함수를 sites 리스트의 항목 중 몇몇에 실행되도록 한다. 메인 프로세스와 다른 프로세스들 간의 통신은 multiprocessing 모듈이 알아서 다룬다.
Pool 객체를 생성하는 부분에 주목해보자. 먼저, 몇 개의 프로세스를 풀에 생성해야 하는지 명시하는 부분이 없다. 직접 지정해줄 수 있는 파라미터 옵션이 있긴 하지만 디폴트로 multiprocessing.Pool()은 사용하는 컴퓨터의 CPU 개수대로 알아서 프로세스들을 생성한다. 이렇게 하는 것이 보통의 경우 최적이며, 이 예제에서도 그렇다.
이 예제에서는 프로세스의 개수를 늘려도 빨라지지 않는다. 오히려 더 느리게 만드는데 이는 I/O 요청들을 병렬적으로 하는데서 오는 이득보다 프로세스들을 생성하고 정리하는데 드는 비용이 더 크기 때문이다.
다음으로 (initializer=정의한 함수) 부분이다. Pool의 각 프로세스는 각자의 메모리 공간을 가진다. 이 말은 Session 객체같은 걸 서로 공유할 수 없다는 말이 된다. 함수가 실행될 때마다 Session 객체를 새로 만드는 건 별로 좋은 방법이 아니다. 각 프로세스마다 하나씩 만들어 주는것이 최적이다.
initializer 파라미터는 이 경우를 위해서 있는 것이다. initializer에 넘겨준 함수의 리턴 값을 download_site()에 넘겨줄 방법은 없지만, 대신 전역 session 변수를 만들어서 각 프로세스가 같은 session을 유지하도록 해줄 수 있다. 각 프로세스는 별도의 메모리 공간을 가지고 있기 때문에, 각 프로세스가 가지는 전역변수는 서로 다르게 된다.
multiprocessing 버전의 장점
multiprocessing 버전은 약간의 코드만 추가하면 되서 상대적으로 구현하기 쉽다. 또 사용자 컴퓨터의 모든 CPU를 사용할 수 있다. 이 버전의 실행 시간 다이어그램을 보자.
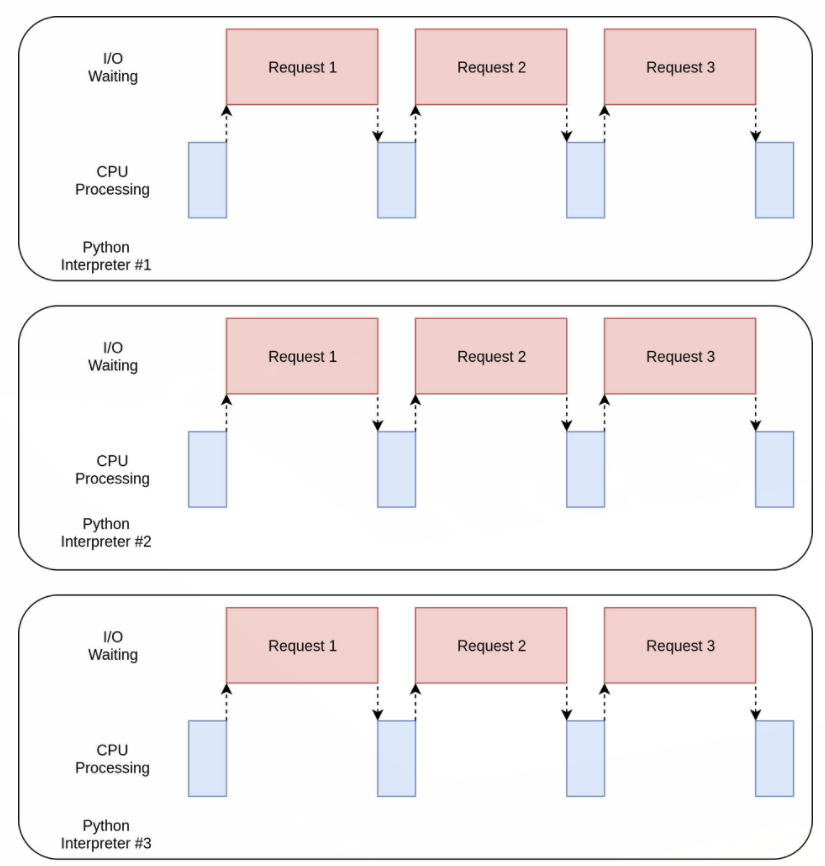
multiprocessing 버전의 문제점
이 버전은 몇몇 추가 작업이 필요하고 전역 변수로 할당한 session 객체가 낯설다. 그래서 어떤 변수가 각 프로세스에 접근할 것인지 많은 생각을 해야 한다. 결과적으로 asyncio와 threading버전에 비해 느리다. 이유는 muliprocessing이 I/O 바운드 작업을 위해 있는게 아니기 때문이다.
CPU 바운드 작업의 속도 개선
지금까지는 모두 I/O 바운드 작업에 대한 한 예제들이었다. 이제 CPU 바운드 작업을 살펴보자. I/O 바운드 작업은 대부분의 시간을 네트워크 호출과 같은 외부 장치가 작업을 처리할 때까지 대기하는데 보냈다. 반면 CPU 바운드 작업은 I/O 작업을 하지 않고 대부분의 시간을 요구된 데이터를 얼마나 빠르게 처리하느냐에 대한 부분이다.
예제를 위해서 CPU를 오래 사용하는 간단한 함수를 하나 만들 것이다. 이 함수는 0부터 받은 수까지의 모든 수를 제곱하여 전부 더하는 함수이다.
def cpu_bound(number):
return sum(i * i for i in range(number))
1. CPU-Bound Synchronous Version
non-concurrent한 동기 버전의 예시를 보자.
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")위 코드는 CPU-bound()를 20번 호출한다. 이 모든 작업을 단일 CPU의 단일 프로세스 안의 단일 스레드에서 작업한다. 실행 시간 다이어그램은 아래와 같다.
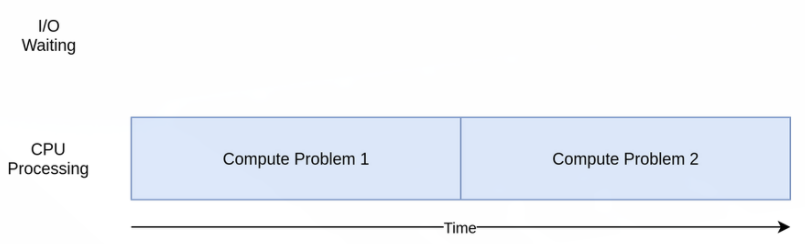
I/O 바운드 예제들과는 달리 CPU 바운드 작업들은 실행시간이 어느정도 일정한 편이다. 이 예제는 6.8초 정도 걸렸다.
이 버전은 CPU 하나를 써서 순차적으로 처리했기 때문에, 확실히 이것보단 빠르게 계산하도록 개선할 수 있을 것이다.
threading과 asyncio 버전
위 예제를 threading과 asyncio버전을 사용하면 얼마나 빨라질까?
I/O 바운드 예제들에서는 대부분의 시간이 느린 외부 작업을 대기하는데 사용되었다. threading과 asyncio버전은 이 대기 시간을 순차적으로 가지는 대신 서로 겹쳐서 전체 대기 시간을 줄인다. 그러나 CPU 바운드 버전은 대기 시간이 없다. 작업을 처리하기 위해 CPU는 계속 돌아가고 있다. 파이썬에서는 Thread와 Task는 같은 CPU의 같은 프로세스에서 실행된다. 즉, 하나의 CPU는 모든 non-concurrent 코드 작업을 수행하면서 Thread 또는 Task를 구성하는 것까지 함께 작업한다. 그 결과 더 많은 시간이 걸린다.
2. CPU-Bound multiprocessing Version
이제 multiprocessing 버전이 빛을 발할 때다. 다른 동시성 라이브러리들과는 다르게 multiprocessing은 무거운 CPU 작업을 여러 CPU에 나눠서 처리하기 위해 고안되었다. 실행 시간 다이어그램은 아래와 같다.
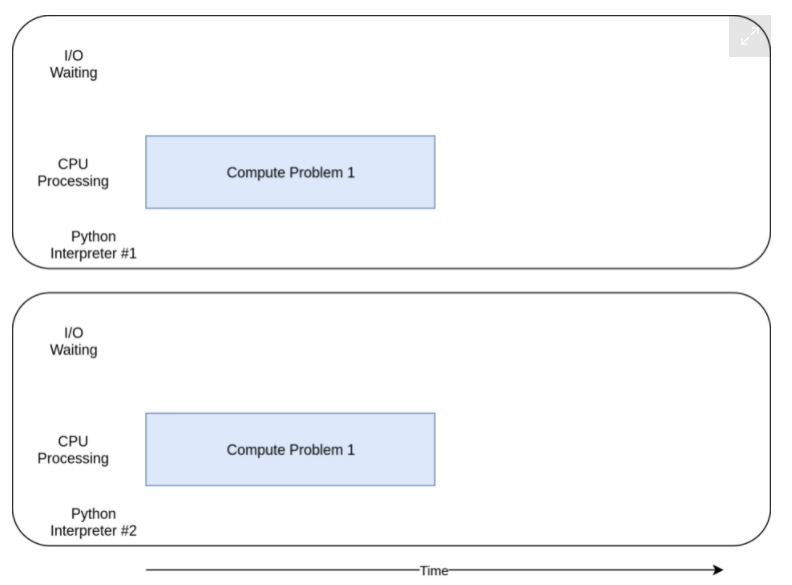
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")위의 동기 버전에서 크게 달라진 건 없다. import multiprocessing를 하고 multiprocessing.Pool 객체를 생성하고 map() 메소드를 사용하여 cpu_bound 함수에 각 숫자들을 맵핑해주었다. 이렇게 하면 각 숫자들을 각 워커 프로세스가 작업을 끝내는 대로 이어서 넘겨주게 된다.
I/O 바운드 multiprocessing 버전의 코드와 같은 걸 해준 것이지만 여기서는 Session에 대해 걱정할 필요가 없다.
multiprocessing 버전의 장점
multiprocessing 버전은 비교적 구현하기 쉽고, 조금의 추가적인 코딩이 필요하기 때문에 좋다. 또 모든 CPU를 사용할 수 있는데서 오는 장점을 누릴 수 있다.
multiprocessing 버전의 문제점
multiprocessing을 사용하는 데는 몇가지 어려움이 있을 수 있다. 이 예제에는 크게 드러나지 않았지만 작업을 분할시켜서 각 프로세서가 작업하도록 하는 것은 때때로 상당히 어려울 수 있다. 또한 대부분의 경우 프로세스들 간 통신을 필요로 하므로 순차적인 프로그램에서는 고민하지 않아도 될 추가적인 복잡성이 발생하게 된다.
When to Use Concurrency
지금까지 많은 것을 알아보았는데, 어떤 동시성 모듈을 사용하면 좋을 지 몇가지 Decision Point을 논의해보자.
첫 단계는 동시성 모듈이 필요한 지부터 정하는 것이다. 예제에서는 간단해 보였지만, 동시성을 프로그램에 추가하는 일은 항상 추가적인 복잡성을 발생시키고 찾기 힘든 버그들을 발생시키게 된다. 동시성을 추가하는 것을 보류하다가 성능 이슈가 발생하면 그 때 어떤 방식으로 동시성을 추가할지를 결정하면 된다. Donald Knuth에 의하면, '조기 최적화는 프로그래밍에서 모든 (또는 적어도 대부분의) 악의 근원이다.'
프로그램을 개선하기로 결정했다면, 프로그램이 CPU-bound 인지 I/O bound 인지를 파악하는 것이 다음 단계다. I/O 바운드 프로그램은 외부 장치의 응답을 대기하는데 대부분의 시간을 쓰는 프로그램이고, CPU 바운드 프로그램은 데이터를 최대한 빠르게 처리하는데 시간을 쓰는 프로그램임을 기억하자.
예제를 통해 알아보았듯이, CPU 바운드 프로그램들은 오직 multiprocessing을 사용해서 개선할 수 있었고, threading과 asyncio는 별 도움이 되지 않았다.
I/O 바운드 프로그램들에 대해서는 파이썬 커뮤니티에서 제시하는 일반적인 규칙이 있다.
'가능하면 asycnio를 쓰고, threading은 꼭 필요할 때 쓰는 것.'이다. asyncio는 이런 프로그램에 대해서 최고의 효율을 뽑아낼 수 있지만, 주요 라이브러리가 asyncio와 호환되도록 되어있지 않다면 곤란해질 수도 있다. 이벤트 루프로 제어권을 넘겨주지 않는 Task가 있다면 그 Task가 전체 프로그램을 Block 할 수도 있다는 점을 기억해야 한다.
참고 및 번역:
https://realpython.com/python-concurrency/#what-is-concurrency
Speed Up Your Python Program With Concurrency – Real Python
Learn what concurrency means in Python and why you might want to use it. You'll see a simple, non-concurrent approach and then look into why you'd want threading, asyncio, or multiprocessing.
realpython.com
https://docs.python.org/ko/3/library/asyncio.html
asyncio — 비동기 I/O — Python 3.10.2 문서
docs.python.org